I the last week one new simulator was released and another one was officially announced. In this blog post I want to discuss what the impact on my various tools will be.
The new simulator that was released is Flight Sim World from Dovetail. After installing the early access version I have come to the conclusion that the MDL and AGN formats are still the same as in FSX. So from that point of view I expect no big changes are needed in my tools to support this simulator as well. However at the moment it’s not clear yet if there will be an official SDK for this simulator. Given that the formats are the same as FSX, I guess we could use the Prepar3D 1.4 SDK, as people with only FSX Steam Edition also have to do. If an SDK is released later on I will check what needs to be done for the tools to support it.
The other new simulator that was announced is Prepar3D v4. The biggest change there is the move to 64 bit. I’m sure there will be an SDK, just as prior Prepar3D versions had. So once it is released I will make sure that my tools can detect and use that SDK as well. As far as I know now, the MDL and AGN file formats have no big changes compared to Prepar3D v3, so I don’t expect big changes are needed to the tools. But once it has been formally released I’ll double check that again.
One note, for both simulators I need to check if the Autogen Configuration Merger tool works well on it. I haven’t checked if the autogen configuration file have changed in FSW and if it has a exe.xml to run a tool on startup like FSX had. That’s something I still need to look into. For Prepar3D v4 I will also need to make sure it’s supported by ACM.
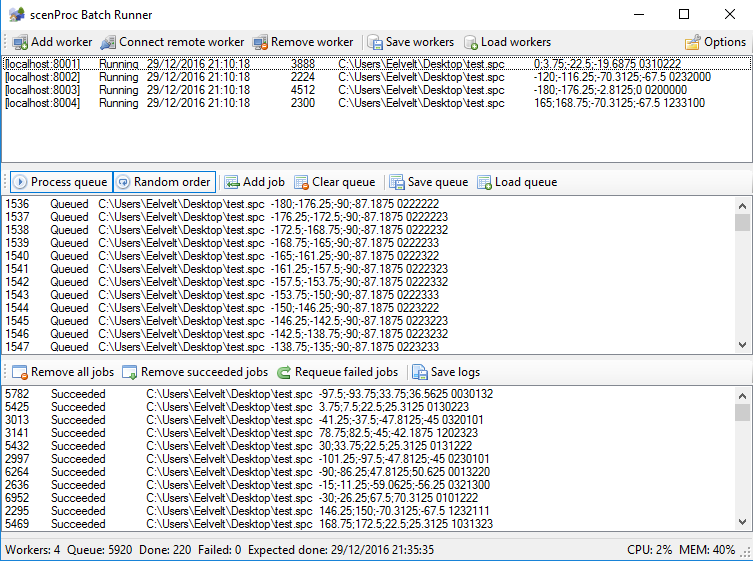
 The end of 2016 is fast approaching, so it’s the time of the year to look back a bit on the last year and look ahead a bit to 2017 as well. For scenProc the last year has been very exiting, with a lot of ideas I had in my head coming to life. But I should also say directly that as users you haven’t seen much from this yet, because most of the new features are currently in a kind of alpha phase and are being tested in a project I’m involved with. In 2017 I hope that these new features will also start to move to the development release. Although I do not have a clear release plan for that in mind yet. But let me use this blog post to shed a bit of light on the possible future of scenProc, by describing some of the things I’m working on.
The end of 2016 is fast approaching, so it’s the time of the year to look back a bit on the last year and look ahead a bit to 2017 as well. For scenProc the last year has been very exiting, with a lot of ideas I had in my head coming to life. But I should also say directly that as users you haven’t seen much from this yet, because most of the new features are currently in a kind of alpha phase and are being tested in a project I’m involved with. In 2017 I hope that these new features will also start to move to the development release. Although I do not have a clear release plan for that in mind yet. But let me use this blog post to shed a bit of light on the possible future of scenProc, by describing some of the things I’m working on.